Bing Tea Search Engine
/ 5 min read

Overview
This project was for EECS 498 - System Design of a Search Engine at UMich. It was by far, the biggest project that I was a part of start to finish. We were a team of 7 and the codebase was around 16000 lines of code. I personally wrote and/or reviewed around 8000 lines of code over a 4 month period. The project consisted of 6 major components:
- HTML Parser
- Crawler
- Inverted Index
- Query Compiler and Expression Parser
- Ranker
- Frontend server
Everything was built from scratch with minimal libraries. External code that we did use were:
- C++ STL
- LibCurl
- spdlog
- argparse
- XGBoost
Edit: We scored the highest LOL
My role
I took on a leadership role within the group, proposing architecture designs, delegating tasks, and making key design decisions. I was primarily involved in the design and implementation of the crawler, inverted index, and the frontend server. I also aided the team building the ranker by doing data collection, cleaning, and labelling.
Architecture Overview
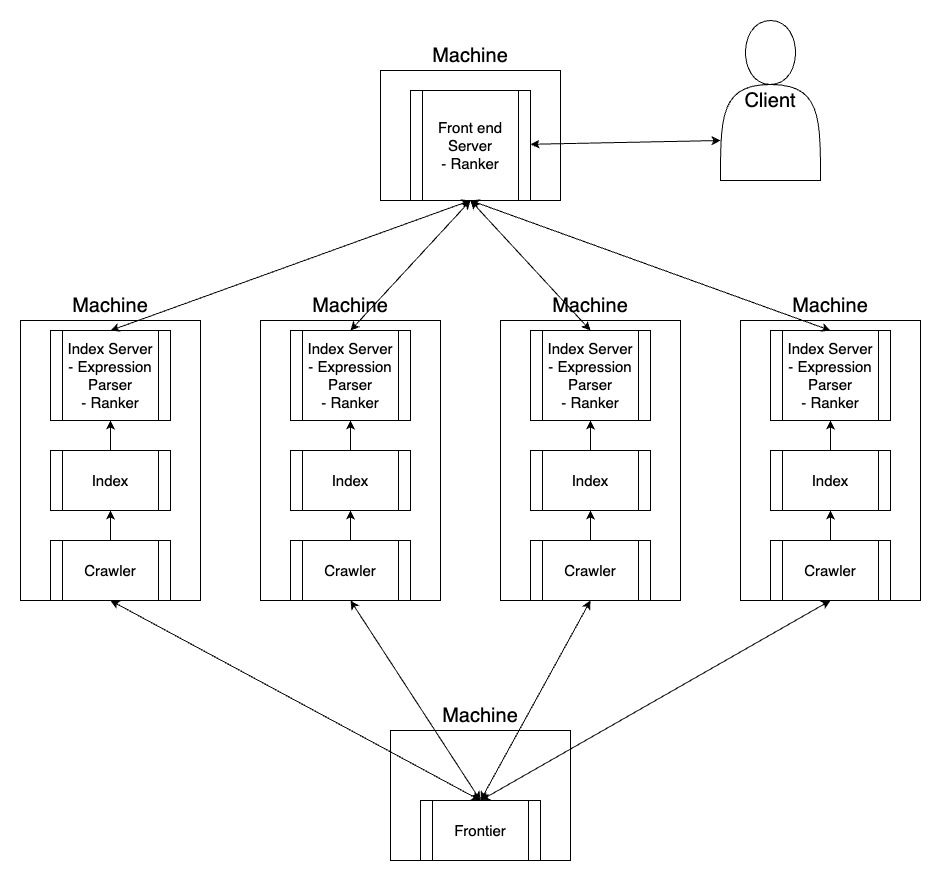 The engine was distributed across 22 virtual machines on GCP. This was done for
the following reasons:
The engine was distributed across 22 virtual machines on GCP. This was done for
the following reasons:
- Couldn’t keep our index on one machine
- Faster crawling and index searches
- Fault tolerance
Each machine ran a crawler, then an indexer, then an index server. The frontend server would serve client search requests by forwarding them to the index servers and serving the best results from the index servers.
Crawler
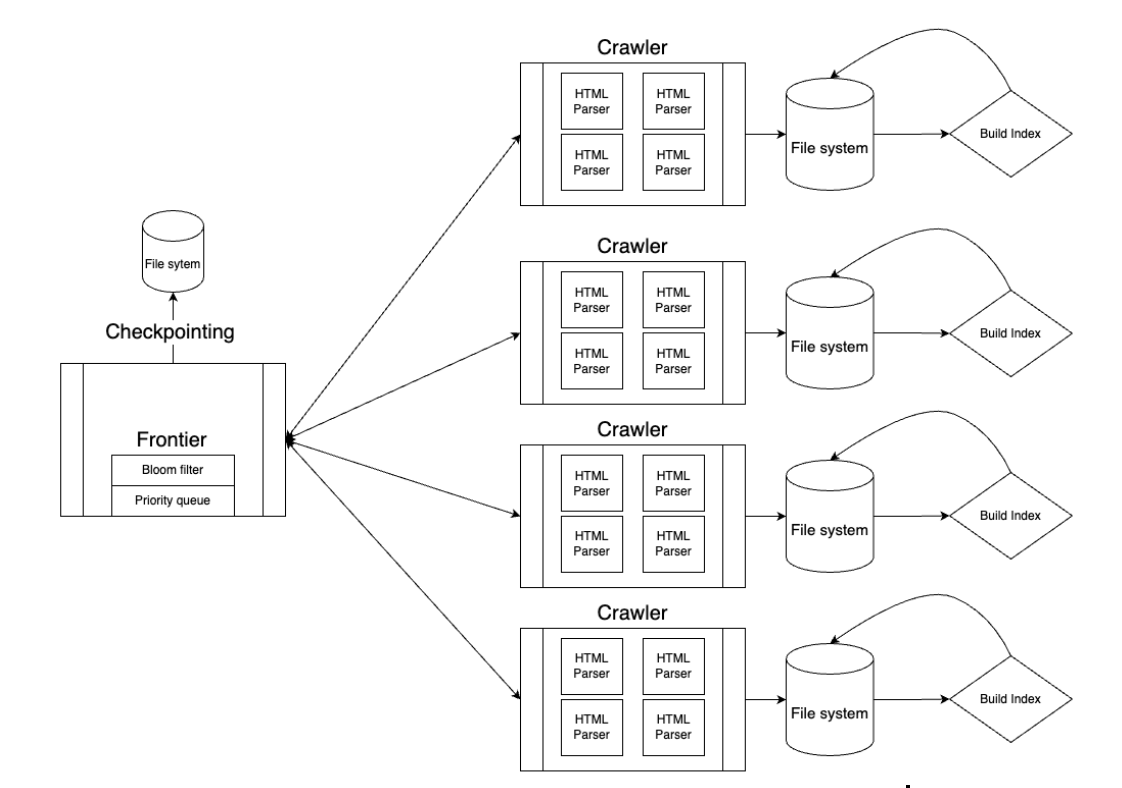
The crawler was composed of a central frontier process that kept track of URLs and crawler processes that downloaded and parsed HTML. The choice to have a central process was made for the following reasons:
- We knew we were crawling on a limited set of machines so scalability wasn’t a big concern. The central process was fast enough to handle requests from all 22 crawlers.
- Easy to add and remove crawlers. Some crawlers were able to download and parse files faster. In order to keep the index sizes relatively similar, we took some crawlers down and let others catch up.
- Global ordering of URLs to crawl next.
The frontier process containted a priority queue with a special heuristic based URL sorting in order to identify the best URLs to crawl next. It also containted a bloom filter that maintained URLs that were already crawled. This bloom filter was periodically written into persistent storage for crash consistency. The frontier sent urls to crawlers in batches of 50, where each crawler would receive 50 urls and send back any urls found in the pages that it parsed.
Each crawler spawns a thread and downloads the page by sending a request with LibCurl. The page is then parsed by a custom HTLM parser that finds the title words, body words, emphasized words, links, and number of images. The parsed page is then stored on disk for indexing later.
While crawling, I had to observe and maintain each process. I was sshed into 22 VMs monitoring logs, cpu usage, and memory usage. Some troubles that we ran into while crawling were
- Crawlers crashing due to malformed HTML files (files contained random bytes instead of text sometimes)
- The frontier running out URLs to send to crawler processes
- Being stuck in a domain for too long This was the closest I felt to being “on
call”. As I ran into these problems, I had to come up with solutions on the fly.
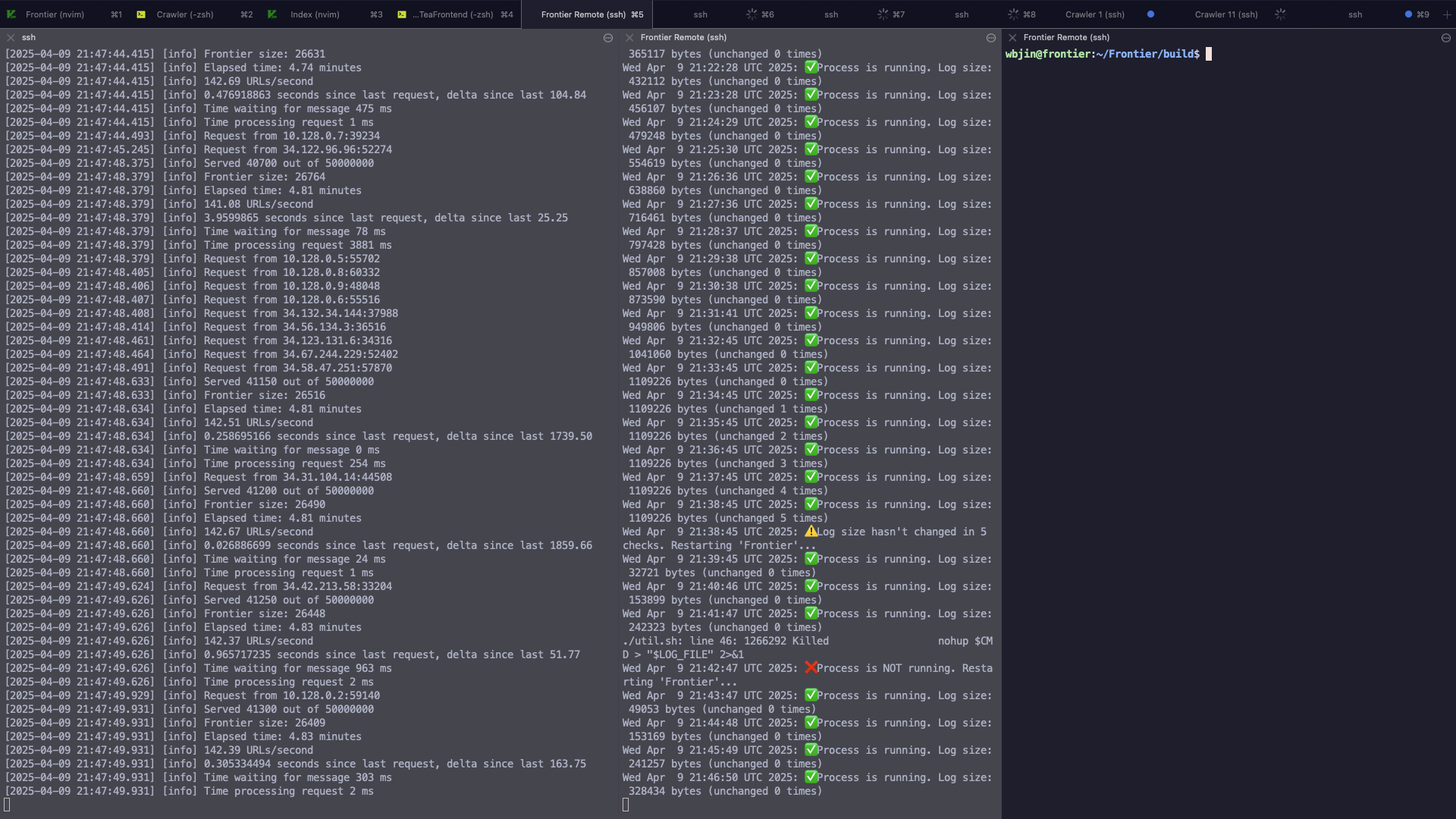
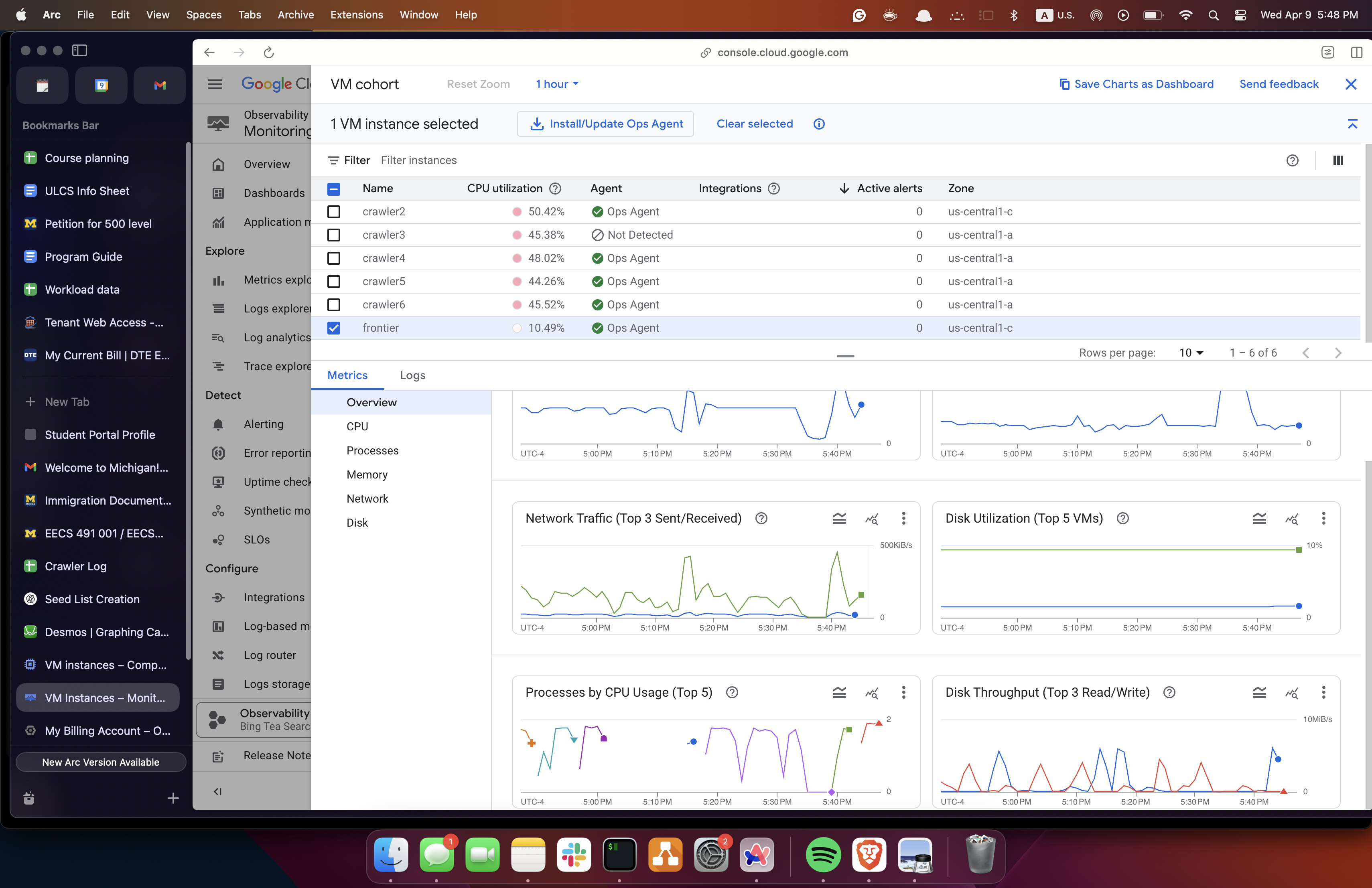
The crawler was able to crawl around 50 million pages at a rate of about 800000 pages per hour. This is about 200 pages per second.
Index
Our entire index was around 50 million documents, 700 GB in size, and contained around 30 billion words. The index maintained a mapping of word to the documents that contained the word and the occurrences within the document. It also maintained metadata such as number of words, page rank, and chei rank for each document. Each index in a machine is broken up into index chunks. A chunk is built by indexing one document at a time until a certain memory threshold is reached. We used memory mapping for fast read and writes to disk.
After indexing the documents, each machine ran an index server that served requests from the frontend server. The frontend server would send a query in string format, the index server parsed the query, searched the index for matches, ranked the document matches, and sent them back to frontend. In order to search efficiently through the index, we kept each index chunk relatively small (100 Mb) in order to keep multiple index chunks within memory and search them concurrently with threads. Each index server was able to search around 80 chunks (800000 documents) concurrently and query times ranged from 100 ms to 1200 ms depending on the query.
Ranker
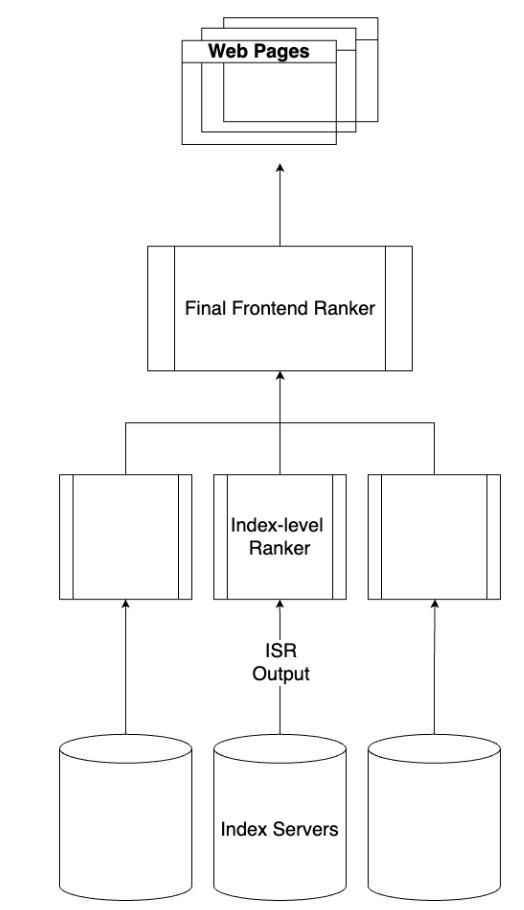 Our ranking involved a two step
process. At the index server level, pages were ranked through a combination of
heuristics. At the frontend server level, we used XGBoost, an ensemble of
decision trees, to give each document a relevance score and ranked based off of
that. Whiel I was not involved in the implementation of the ranker, I aided a
lot in data retrieval.
Our ranking involved a two step
process. At the index server level, pages were ranked through a combination of
heuristics. At the frontend server level, we used XGBoost, an ensemble of
decision trees, to give each document a relevance score and ranked based off of
that. Whiel I was not involved in the implementation of the ranker, I aided a
lot in data retrieval.
Some heuristics that we had were page rank, chei rank, and louvain communities. I wrote many scripts in C++ and Python that cleaned and labelled the data needed to run the algorithms for calculating these heuristic scores. I also aided in sourcing training data for XGBoost.
For a demo and more information, checkout our slides and final project report.